SignLLM: Sign Languages Production Large Language Models
|
1Rutgers University
|
2Australian National University
|
3Data61/CSIRO
|
4Carnegie Mellon University
|
|
5Columbia University
|
6University of Texas at Dallas
|
7University of Central Florida
|
|
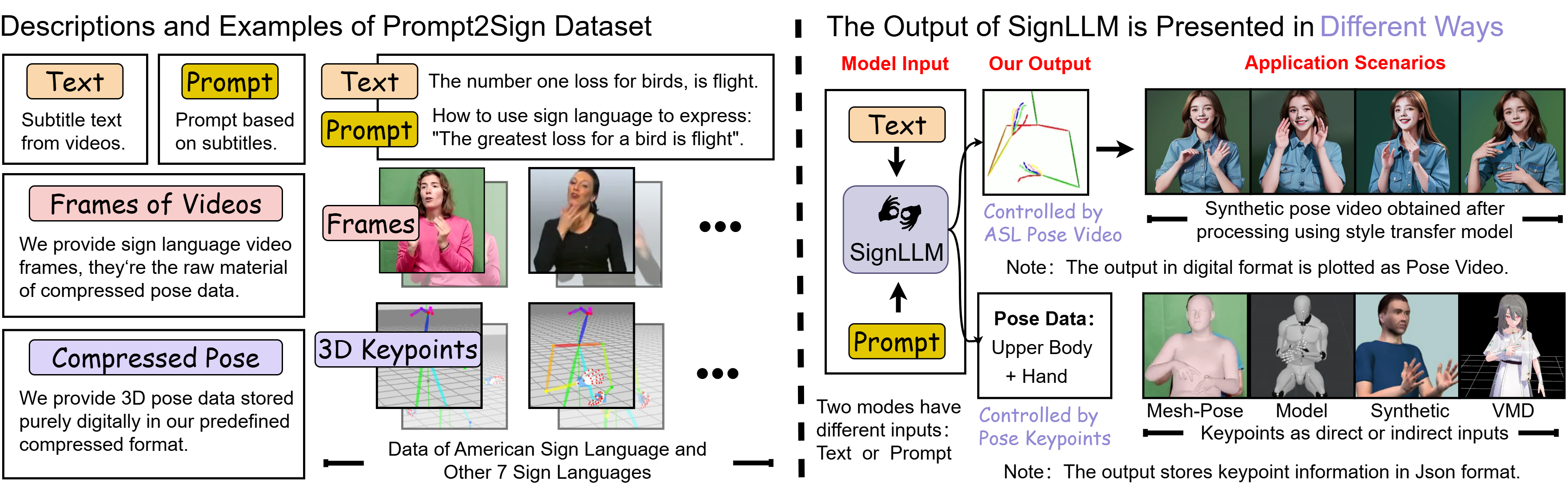
Overview: (Left) Major components(e.g., Text, Prompt, Compressed Pose, etc.) of Prompt2Sign dataset. Compressed Pose is reprocessed pose data that is suitable for training, we use public sign language videos to produce compressed pose data in our predefined format; (Right) Our proposed SignLLM aims to generate sign language poses for various application scenarios.
|

Paper
|

Prompt2Sign (tools)
|

Additional details
|

Methodology
|

Code (stay tuned)
|
Subscribe to the latest news of SignLLM by Twitter.
In this paper, we propose SignLLM, a multilingual Sign Language Production (SLP) large language model, which includes two novel multilingual SLP modes MLSF and Prompt2LangGloss that allow sign language gestures generation from query texts input and question-style prompts input respectively. Both modes can use a new RL loss based on reinforcement learning and a new RL module named Priority Learning Channel. These RL components can accelerate the training by enhancing the model's capability to sample high-quality data. For SignLLM's training, we introduce Prompt2Sign, a comprehensive multilingual sign language dataset, which builds from public data, including American Sign Language (ASL) and seven others. This dataset standardizes information by extracting pose information from sign language videos into a unified compressed format. We extensively evaluate SignLLM, demonstrating that our model achieves state-of-the-art performance on SLP tasks across eight sign languages.
Besides the abstract, you can also read the unofficial English or Chinese paper interpretation.
Demo Video
|
|
|
|
|
|
|
|
|
DEMO: We give some examples of better prediction results, below each video is their input text.
|
Qualitative Presentation (Multilingual)
|
|
|
|
|
|
ASL
|
DGS
|
KSL
|
DSGS
|
|
|
|
|
|
|
LSF-CH
|
LIS-CH
|
LSA
|
TSL
|
QP: Synthetic sign language video generated through style transfer modeling (intermediate input video has undergone processing like acceleration and rendering; results under Ideal Future Conditions).
|
Main Method
|
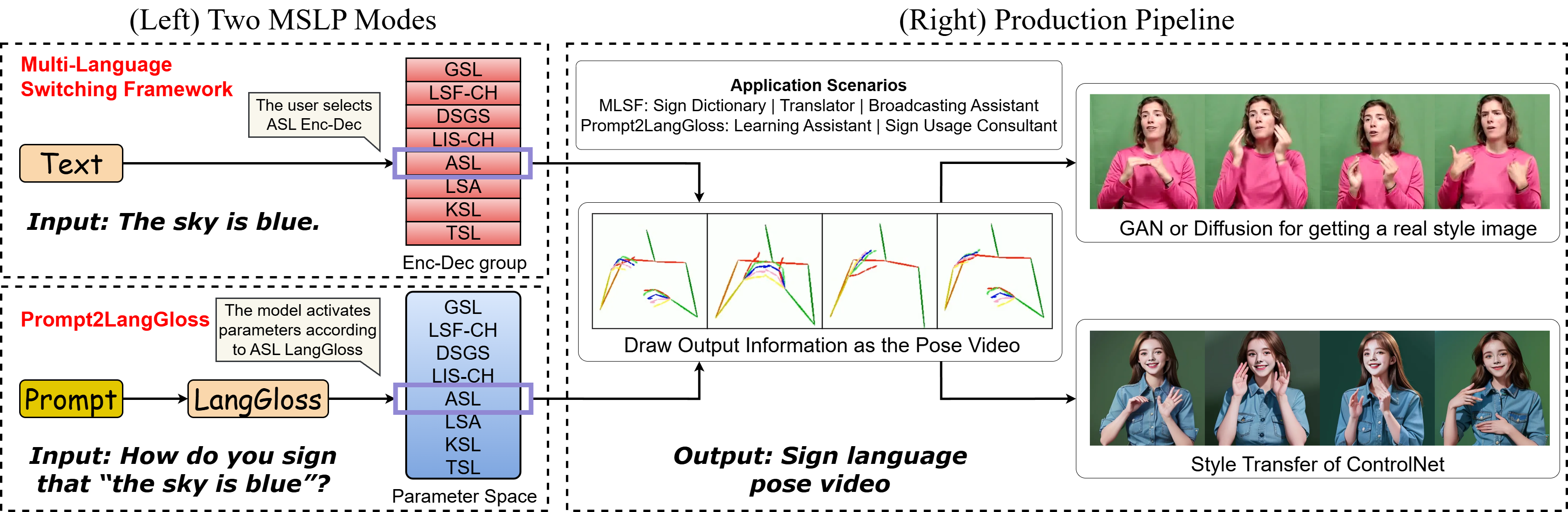
(Left) MLSF contains parallel Enc-Dec groups (i.e., Text2Pose × number of languages), the Prompt2LangGloss adds a language attribute marker at the gloss channel (i.e., Text2Gloss2Pose → Prompt2LangGloss2Pose).
(Right) The output of SignLLM can be converted into a skeletal pose video, which can then be rendered into a realistic human appearance by vid2vid models.
|
Other Method
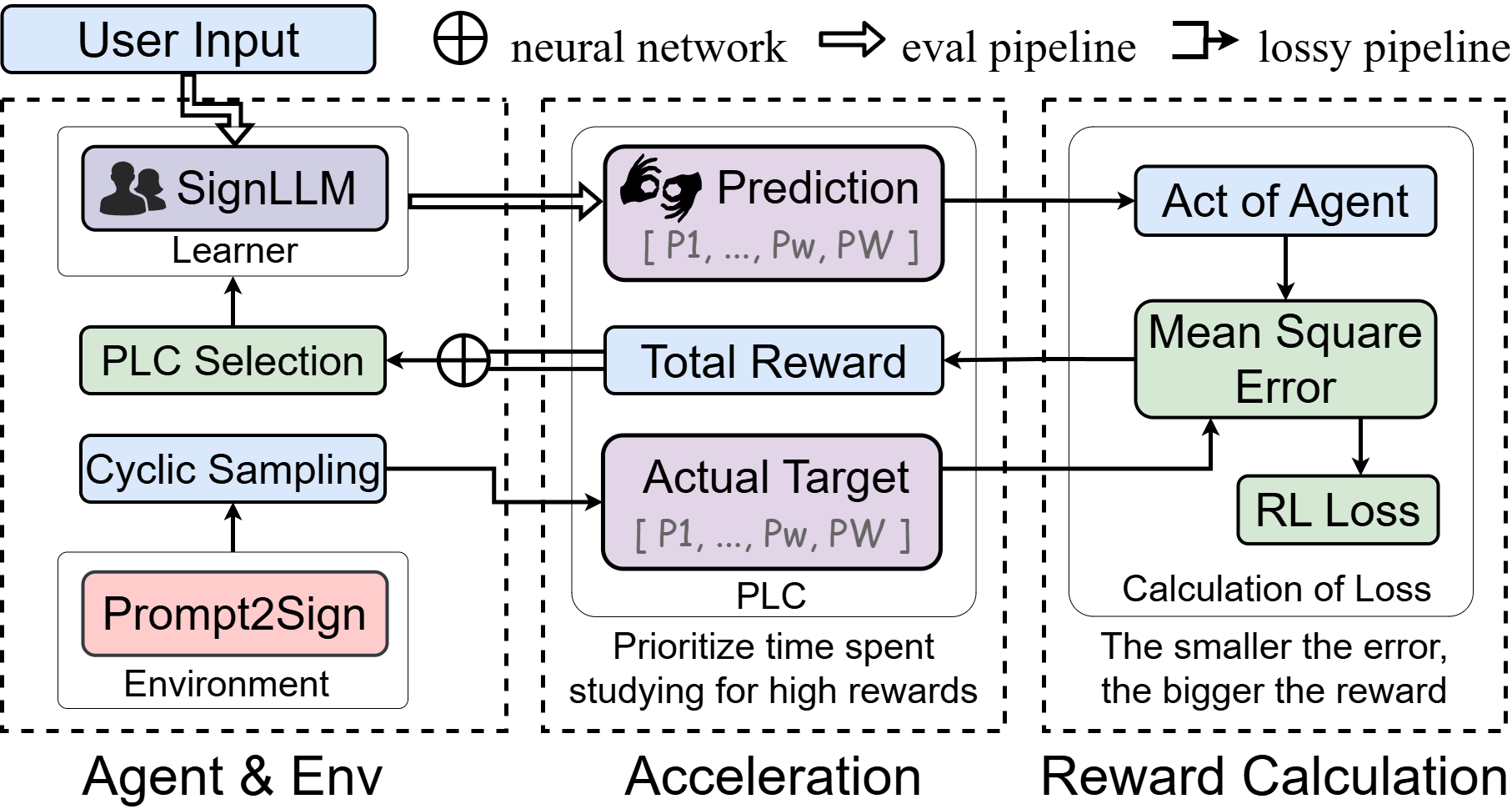
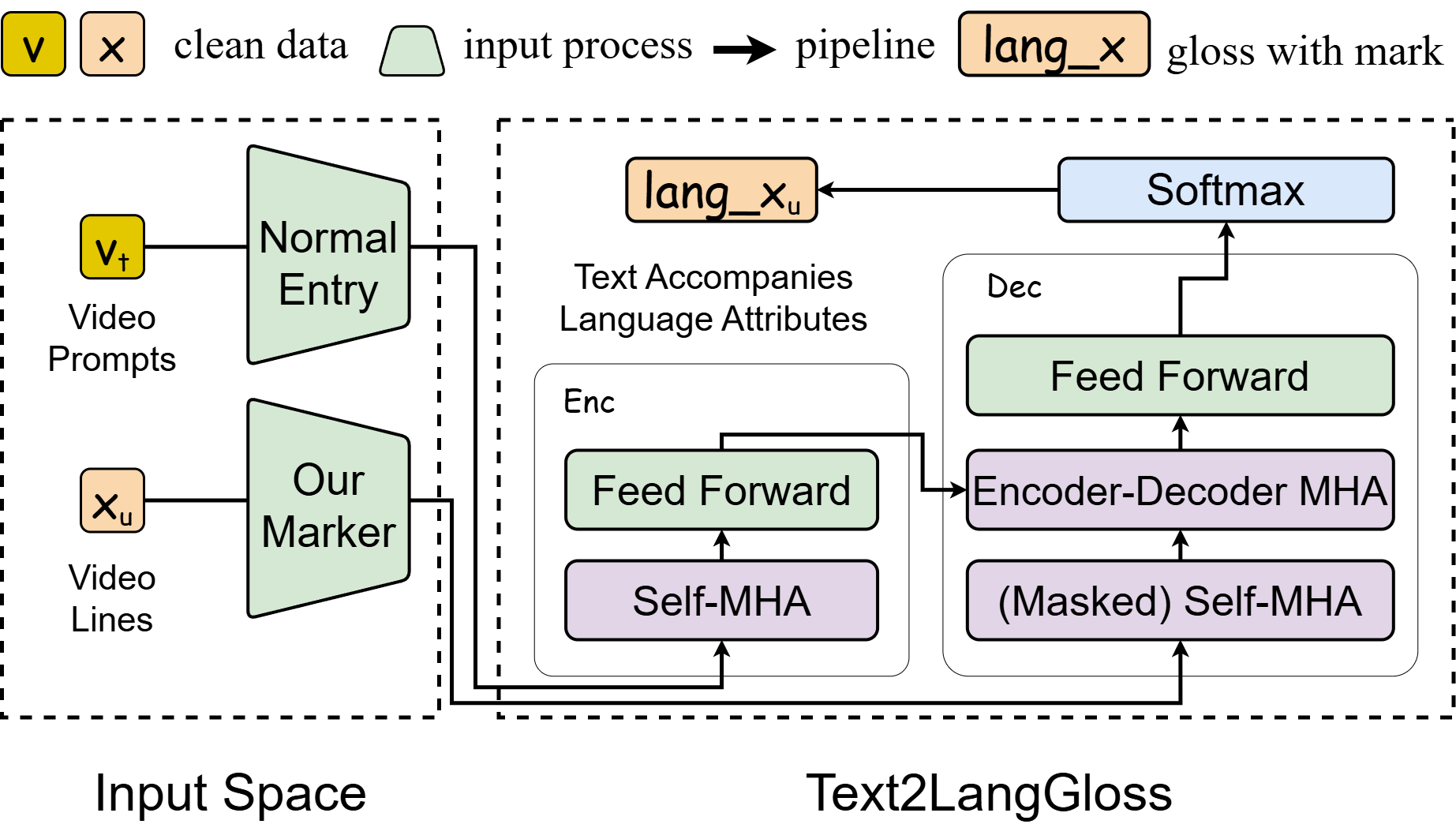
In our work, we have improved upon the Text2Gloss framework by incorporating a marker that produces Gloss with the necessary linguistic attributes,
while also representing profound characteristics through variables Vt and Xu within neural networks. Additionally,
we have introduced five key elements—user, agent, environment, iterative update process,
and PLC—which collectively outline a reinforcement learning process tailored for sequence prediction.
|
|
Empirical Studies and Analysis
(1) American Sign Language Production (ASLP).
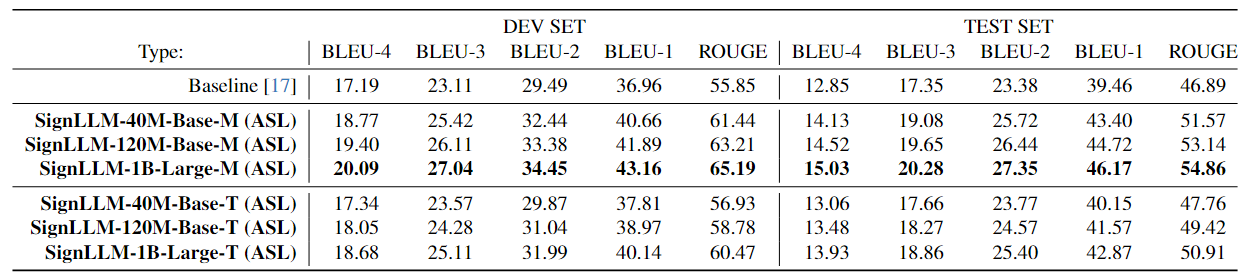
|
|
Comparison of different models of SignLLM with baseline. Models M and T represent MLSF and Text2LangGloss trained ASLP models, respectively.
|
(2) German Sign Language Production (GSLP).
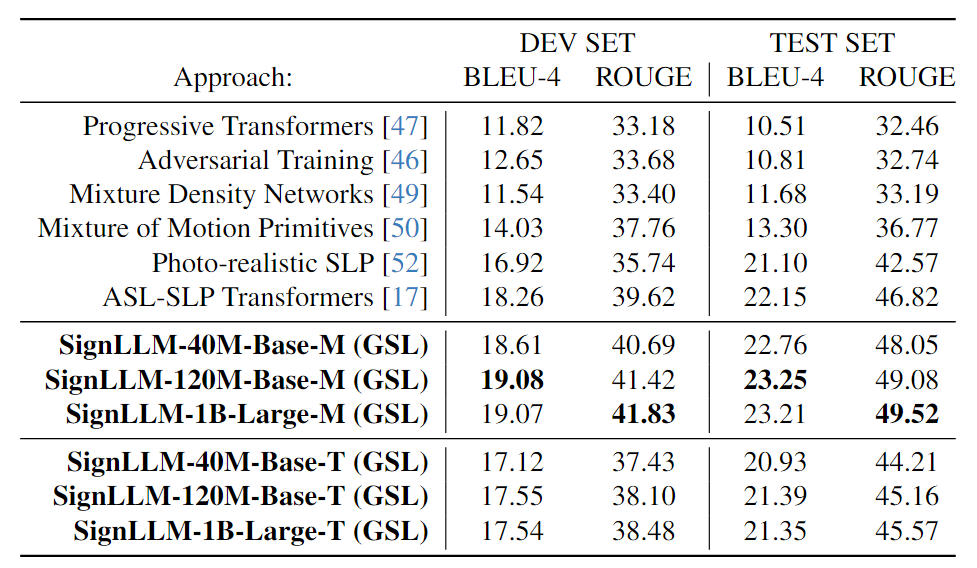
|
|
Comparison of different models of SignLLM with previous work.
|
(3) Ablation Study.
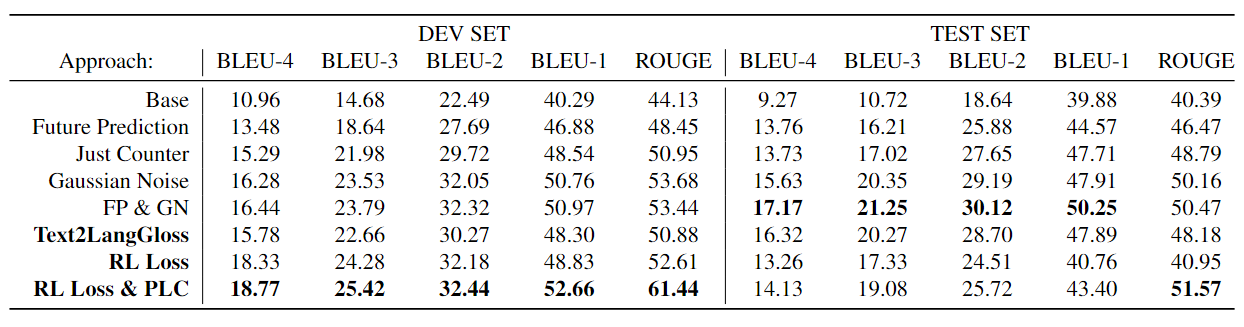
|
|
SignLLM-40M-Base results for Text to Pose on the ASL part of Prompt2Sign, with multiple data augmentation techniques. Base:
Multi-Language Switching Framework with Normal MSE Loss, FP: Future Prediction, GN: Gaussian Noise, Text2LangGloss:
Text2LangGloss with Normal MSE Loss, PLC: Priority Learning Channe
|
(4) Training Efficiency Study.
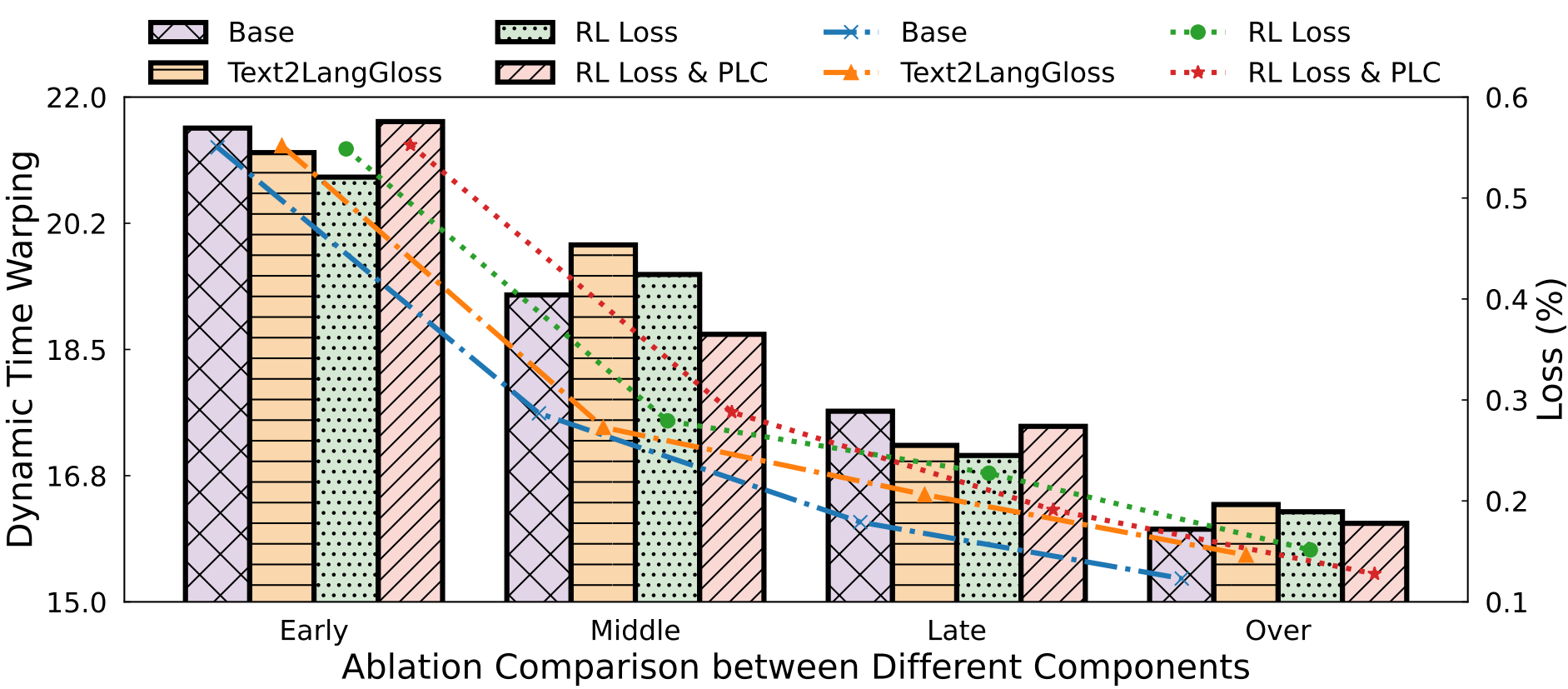
|
|
the comparison of the effect of different Settings on DTW values (the lower the better) at different times is determined by epoch.
|
Updates
[2025.05.24] We have recently developed a tool named fast_dwpose for minimizing the extraction and visualization of DW Pose, and we hope it will be helpful to everyone.
[2025.04.18] Surprise: We have released How2Sign new compressed data based on DWPose, and an upgraded version of the SignLLM-based application will be launched strongly in the future.
[2025.04.01] IMPORTANT: We will try to provide a new compression solution (maybe based DWpose) at some point. Therefore, for unreleased preprocessed data and for existing data processing, the best approach is to download the original dataset and then process it using our processing tools.
[2025.03.31] The prompt template has been updated, more data information has been updated. In the past, I've been wanting to optimize filtering, re-normalize according to body type and improve data quality, this make me have severe procrastination. And later I noticed that DWpose might be a better training method, so unreleased data will not be maintained because our time should spent on better data formats.
[2024.06.30] The Jupyer Notebook and Docker for data processing has been released.
[2024.05.17] The arXiv version of the paper is now available.
[2024.01.16] Prompt2Sign homepage is available and data is expected to be released after accept (maybe at the end of 2024, so don't rush).
[2023.12.14] We have made supplementary materials and demo available at this page.
[2023.11.04] We have made Prompt2Sign and Tools available at GitHub. Check out here.
FAQs
Q0: License issue:
A0: The Prompt2Sign and SignLLM are copyright by us and published under the Creative Commons Attribution-NonCommercial 4.0 International License. Some subsets need to be implemented by users themselves.
Q1: Some links are invalid on page. How can I obtain the missing information?
Q1: I am located in mainland China and I cannot access Google Driver. How can I get the dataset?
A1: Please submit a GitHub issue at Any repository of user "SignLLM".
We may reach you shortly.
Q2: Is the data in the data set complete relative to the original video? I feel like it's smaller than the actual data set.
A2: We're using a dataset that is a subset of the video clips that correspond to the lines and then we compress those clips. Compression to 1/5 of the original size refers to 1/5 of the size of the clip.
Q3: Can we fully achieve the actual effect in the paper or presentation?
A3: No, according to the data and the actual situation, most of our cases are not up to the level of use. Dynamic or static display, we are selected to show the best effect.
Q4: How to complete the data conversion format? Specific to the level of each number. Too much remains unclear.
A4: You can look at the dataset itself and the tools, with an example and plenty of text describing it in detail.
How to finish data format conversion (JSON->Ours)?
Below, we show an example JSON:
### JSON file:
{
"version": 1.3,
"people": [
{
"person_id": [
-1
],
"pose_keypoints_2d": [
666.535,
219.883,
...
# We only get eight key points in the upper body(24 number).
],
"face_keypoints_2d": [
624.108,
204.299,
0.813047,
# We don't train the face.
],
"hand_left_keypoints_2d": [
694.829,
455.679,
0.352355,
...
# 21 key points, 63 values.
],
"hand_right_keypoints_2d": [
516.344,
348.757,
0.0184774,
...
// 21 key points, 63 values.
],
"pose_keypoints_3d": [],
"face_keypoints_3d": [],
"hand_left_keypoints_3d": [],
"hand_right_keypoints_3d": []
}
]
}
How to extract key points? We extracted two-dimensional (2D) frontal human pose information from videos of different resolutions, including upper body pose information of the body and hands, through OpenPose. Includes 8 upper body key points. 21 keypoints in each hand, which is a total of 42 hand keypoints. These two parts add up to fifty keypoints, each of which has three XYZ messages, or 150 numbers.
Then in steps ``json (2D keypoints) to h5'', ``h5 to txt (3D keypoints)'', and ``txt to skels (Standard Pose Storage)'':
How to complete ``json to h5''? We successively obtain a json number in a folder (a frame of pose information, 50 key points, 150 numbers), and then read all the json numbers in a folder into the key name of an h5 (h5 is a format of numpy) file, multiple folders form multiple build names, and finally form an h5 file.
How to complete ``h5 to txt''? We read each key name of h5 in turn (the original folder name), create the corresponding folder, each folder generates 5 txt files, the last one is the result, the first 4 txt stores the intermediate variable. This is the part of 2D to 3D, and the key formula 3 in the text is the formula of this part. Additionally, we read the relevant data and delete the unqualified data such as NaN, 0, or replace it with the average median of the data. Finally, we condensed the data to about 1/5 of the original, this data comes from the processing of ASL part.
How to complete ``txt to skels''? We read the fifth txt file of each folder in turn, the number of lines in the txt file represents the number of frames of the folder corresponding to the video, we read a line of txt (150 numbers, separated by Spaces, a frame of information), plus a space, and then add a count value (the current line divided by the total number of lines, representing the progress bar), add a space after the count value, Then add the second line txt and continue to repeat the above. Then we put a txt (a video information, the total number of numbers in it = 151* video frames) into a line of content, in turn, tens of thousands of videos are all stored in our standard format.
How to complete h5 to txt conversion?
Above you mentioned TXT folder 12345, but what is TXT5? Below, we show an example the above data processing process:
def getTXT(key, fnameIn, i, mode):
output_file = f"out_data/{mode}/{key}/demo5.txt"
if os.path.exists(output_file):
print(f"Skipping {key} as output file already exists.")
return
else:
# Getting our structure of skeletal model.
# For customizing the structure see a definition of getSkeletalModelStructure.
dtype = "float32"
randomNubersGenerator = numpy.random.RandomState(1234)
structure = skeletalModel.getSkeletalModelStructure()
with h5py.File(fnameIn, "r") as hfIn:
print("")
print("Now is processing the "+ key)
print("")
inputSequence_2D = numpy.array(hfIn.get(key))
# Decomposition of the single matrix into three matrices: x, y, w (=likelihood)
X = inputSequence_2D
print(X.shape)
Xx = X[0:X.shape[0], 0:(X.shape[1]):3]
Xy = X[0:X.shape[0], 1:(X.shape[1]):3]
Xw = X[0:X.shape[0], 2:(X.shape[1]):3]
# Normalization of the picture (x and y axis has the same scale)
Xx, Xy = pose2D.normalization(Xx, Xy)
save(f"out_data/{mode}/{key}/demo1.txt", [Xx, Xy, Xw])
# Delete all skeletal models which have a lot of missing parts.
Xx, Xy, Xw = pose2D.prune(Xx, Xy, Xw, (0, 1, 2, 3, 4, 5, 6, 7), 0.3, dtype)
save(f"out_data/{mode}/{key}/demo2.txt", [Xx, Xy, Xw])
# Preliminary filtering: weighted linear interpolation of missing points.
Xx, Xy, Xw = pose2D.interpolation(Xx, Xy, Xw, 0.99, dtype)
save(f"out_data/{mode}/{key}/demo3.txt", [Xx, Xy, Xw])
# Initial 3D pose estimation
... = pose2Dto3D.initialization(
...
)
save(f"out_data/{mode}/{key}/demo4.txt", [Yx0, Yy0, Yz0])
# Backpropagation-based filtering
Yx, Yy, Yz = pose3D.backpropagationBasedFiltering(
...
)
save(f"out_data/{mode}/{key}/demo5.txt", [Yx, Yy, Yz])
# Called after each folder is processed to release GPU resources
print(f"Now we're working on folder {i} th, and will be finished")
i=i+1
tf.keras.backend.clear_session()
The above code shows the contents of our several TXT files, and it clearly shows that 1234 is mainly to store intermediate variables and related content, the fifth folder is the final product we need.
And for more details, see the official documentation.
Cite
@misc{fang2025signllmsignlanguageproduction,
title={SignLLM: Sign Language Production Large Language Models},
author={Sen Fang and Chen Chen and Lei Wang and Ce Zheng and Chunyu Sui and Yapeng Tian},
year={2025},
eprint={2405.10718},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2405.10718},
}
Acknowledgements
We sincerely appreciate the previous work, open source tools, and researchers for underserved populations. We stand on the shoulders of their work to achieve further achievements. Readers can learn how we utilize and improve previous work through our citations.
Additionally, we have noticed spontaneous promotion from over 80-120 marketing media outlets and independent content creators, but they may have some misconceptions or exaggerations about our model. Our model takes input text or prompts to generate videos of sign language pose in various languages. Certain conditions need to be input into the model for further processing to obtain the final videos, so we need to work even harder to strengthen the end-to-end capabilities (ie, the pose video output from the model needs to be processed to achieve the effect of real people).
We are grateful to our supporters including Microsoft, Amazon, Swiss TV, as well as organizations and accessibility practitioners worldwide for their continued support.
|
Contact
For further questions and suggestions, please only contact Sen Fang or SignLLM.
|

